견고한 데이터 엔지니어링
- 데이터 아키텍트를 위한 교과서 -

최근 인공지능과 빅데이터가 중요해지고, ChatGPT, Bard, Lamma, DALL-E 등 생성형 인공지능이 사회에 커다란 파란을 일으키면서 데이터 아키텍트에 대한 중요성도 높아지고 있습니다. 생성형 인공지능을 만들기 위해서는 잘 정제된 초대형 데이터가 필요하고 그것을 다루기 위해서는 데이터 아키텍트의 역할이 중요하기 때문입니다. 이러한 사회적 요구에 의해 최근 데이터 아키텍트, 데이터 엔지니어링 분야가 아주 각광을 받고 있고, 몸값도 상상 이상으로 높아지고 있는데요. 마침 한빛미디어에서 데이터 엔지니어링에 대한 신간이 출간되었습니다. 읽어 본 소감을 결론부터 말하자면,
최근들어 중요해진 데이터 엔지니어링 분야의 교과서 라고 할 수 있습니다.
1. 누가 읽어야 하나요?
데이터 엔지니어닝, 데이터 아키텍쳐 전문가를 꿈꾸는 사람. 데이터 분석 관련 직종 혹은 데이터 분석쪽으로 공부하고 싶은 사람. 데이터 수집과 저장에 대해서 자세히 배우고 싶은 사람들에게 추천합니다.
데이터 엔지니어링 관련 자격증인
데이터아키텍처 전문가 (DAP : Data Architecture Professional)
데이터아키텍처 준전문가 (DAsP : Data Architecture semi-Professional)
를 취득하기 위해서 준비하는 학생들에게도 아주 유용합니다.
2. 책의 내용 구성
책의 내용은 데이터 엔지니어링에 대한 이론과 실무 경험에서 나온 다양한 시스템별 차이점과 비교점에 대해서 아주 자세하게 설명합니다. 각 챕터 뒷쪽에는 다양한 논문과 책 출처가 있어서 추가적으로 공부하고 싶을 때 자료를 찾아보기에도 아주 좋게 되어 있습니다.
단, 개념 설명이 많기 때문에 쉽게 읽히는 책은 아닙니다. 생소한 용어와 방대한 지식을 다 익히기 위해서는 여러 번 두고두고 읽어야 하는 책입니다.
각 챕터별 내용은 아래와 같습니다.
[PART I 데이터 엔지니어링 기반 구축하기]
CHAPTER 1 데이터 엔지니어링 상세
데이터 엔지니어링이 무엇인지, 데이터 엔지니어링의 정의, 데이터 엔지니어링 라이프사이클, 데이터 엔지니어의 진화, 데이터 엔지니어링과 데이터 과학, 데이터 엔지니어링 기술 및 활동, 데이터 성숙도와 데이터 엔지니어, 데이터 엔지니어의 배경 및 기술, 비즈니스 책임, 기술 책임 등에 대해 다룹니다
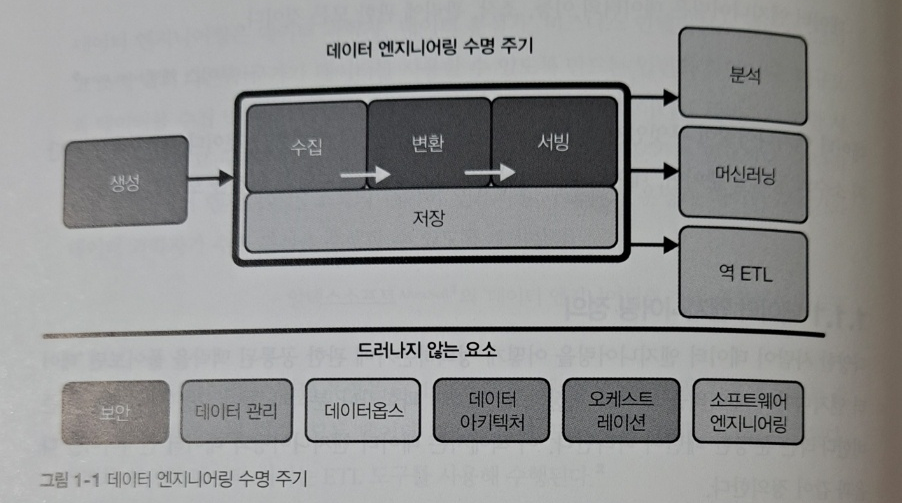
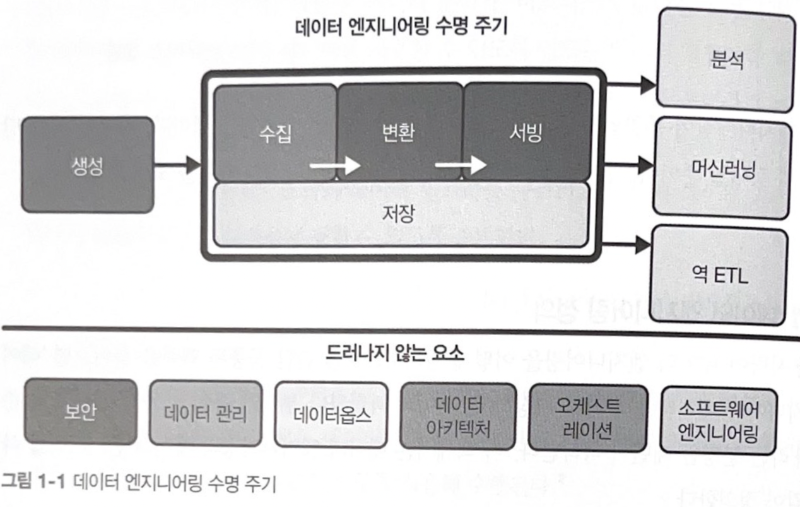
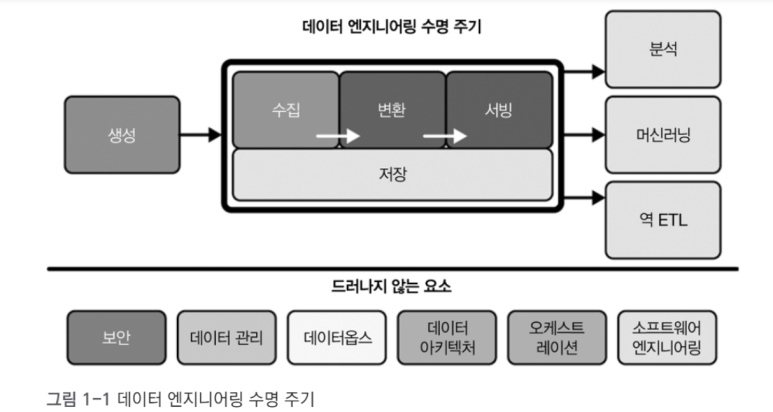
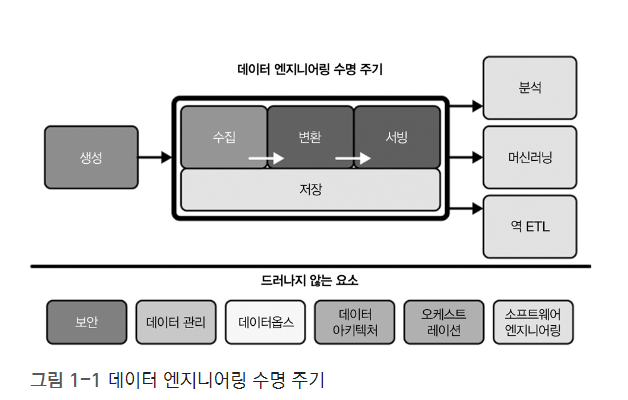
CHAPTER 2 데이터 엔지니어링 수명 주기
데이터 엔지니어링 라이프사이클이 무엇인지, 데이터 라이프사이클과 데이터 엔지니어링 라이프사이클의 차이점, 생성: 소스 시스템 저장소 수집 변환 서빙 데이터 등에 대해 다룹니다
CHAPTER 3 우수한 데이터 아키텍처 설계
데이터 아키텍처가 무엇인지에 대해 다룹니다
CHAPTER 4 데이터 엔지니어링 수명 주기 전체에 걸친 기술 선택
데이터 엔지니어링 수명 주기 전체에 걸친 기술 선택에 대해 다룹니다. 이 장에서는 팀의 규모와 능력, 시장 출시 속도, 상호 운용성, 비용 최적화 및 비즈니스 가치, 현재 vs 미래: 불변의 기술과 일시적 기술 비교, 장소: 온프레미스, 클라우드, 하이브리드 클라우드, 멀티클라우드, 구축과 구매 비교, 모놀리식과 모듈식 비교, 서버리스와 서버 비교, 최적화, 성능, 벤치마크 전쟁 등에 대해 다룹니다.
[PART II 데이터 엔지니어링 수명 주기 심층 분석]
CHAPTER 5 1단계: 원천 시스템에서의 데이터 생성
원천 시스템에서의 데이터 생성에 대해 다룹니다. 이 장에서는 데이터 원천: 데이터는 어떻게 생성될까?, 원천 시스템: 주요 아이디어, 원천 시스템의 실질적인 세부 사항, 함께 작업할 대상 등에 대해 다룹니다.
CHAPTER 6 2단계: 데이터 저장
데이터 저장에 대해 다룹니다. 이 장에서는 데이터 스토리지의 기본 구성 요소, 데이터 스토리지 시스템, 데이터 엔지니어링 스토리지 개요, 스토리지의 주요 아이디어와 동향 등에 대해 다룹니다.
CHAPTER 7 3단계: 데이터 수집
데이터 수집에 대해 다룹니다. 이 장에서는 데이터 수집이란?, 수집 단계의 주요 엔지니어링 고려 사항, 배치 수집 고려 사항, 메시지 및 스트림 수집에 관한 고려 사항 등에 대해 다룹니다.
CHAPTER 8 4단계: 쿼리 모델링 및 데이터 변환
쿼리 모델링 및 데이터 변환에 대해 다룹니다. 이 장에서는 쿼리, 데이터 모델링, 변환 등에 대해 다룹니다.
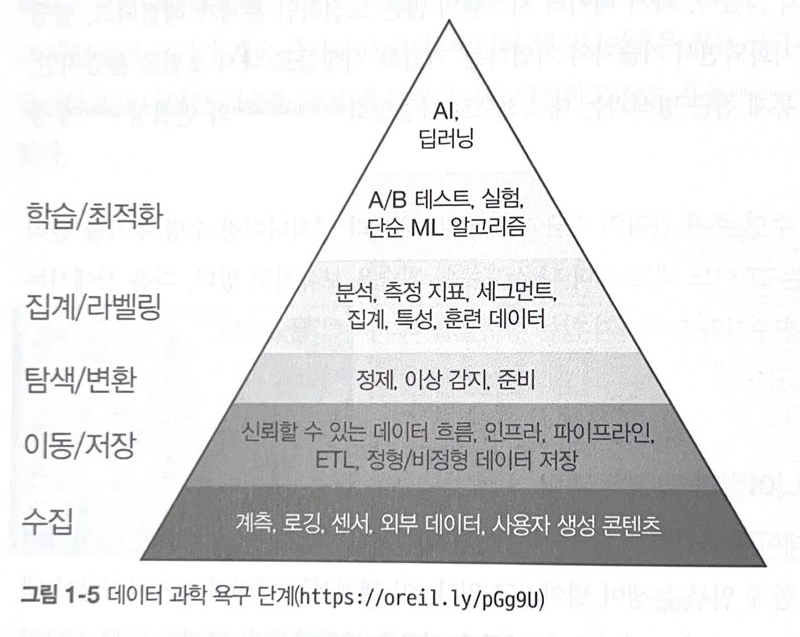
CHAPTER 9 5단계: 분석, 머신러닝 및 역 ETL을 위한 데이터 서빙
분석, 머신러닝 및 역 ETL을 위한 데이터 서빙에 대해 다룹니다. 이 장에서는 데이터 서빙의 일반적인 고려 사항, 분석, 머신러닝 등에 대해 다룹니다.
[PART III 보안, 개인정보보호 및 데이터 엔지니어링의 미래]
CHAPTER 10 보안과 개인정보보호
보안과 개인정보보호에 대해 다룹니다. 이 장에서는 사람, 프로세스, 기술 등에 대해 다룹니다.
CHAPTER 11 데이터 엔지니어링의 미래
데이터 엔지니어링의 미래에 대해 다룹니다. 이 장에서는 사라지지 않는 데이터 엔지니어링 수명 주기, 복잡성의 감소와 사용하기 쉬운 데이터 도구의 부상, 클라우드 규모의 데이터 OS와 향상된 상호 운용성, ‘엔터프라이즈’ 데이터 엔지니어링, 직책과 책임의 변화, 모던 데이터 스택을 넘어 라이브 데이터 스택으로 등에 대해 다룹니다.
APPENDIX A 직렬화와 압축 기술 상세
APPENDIX B 클라우드 네트워킹
3. 마무리
견고한 데이터 엔지니어링은 최근들어 중요해진 데이터 엔지니어링 분야의 교과서 라고 할 수 있습니다. 방대한 내용을 담고 있으며 추가적인 학습을 위한 세부 개념에 대한 출처를 모두 표기하고 있으며, 실무를 통해서만 알 수 있는 스토리지별 차이점, 효율적인 쿼리 작성 등에 대한 내용도 상세히 소개 하고 있습니다.
데이터 엔지니어링은 데이터의 수집, 저장, 전처리를 전문적으로 하는 영역입니다. 저자가 책 앞부분에서 이야기 하고 있듯
'데이터 엔지니어링'은 데이터 엔지니어가 데이터를 가져와 저장하고, 데이터 과학자나 분석가 등이 사용할 수 있도록 준비한다.
다른 어느 때 보다 데이터의 양과 품질이 중요해진 시대에 원본 데이터를 수집하면서도 고 퀄리티를 유지할 수 있도록 가공하고 분석가들에게 데이터 전처리에 대한 부담을 지우지 않도록 사전에 처리해 주는 역할을 합니다.
최근들어 주목받고 있는 데이터 엔지니어링에 대해서 이렇게 상세하고 방대한 지식을 전달해주는 책이 출간되어 기쁩니다. 데이터 엔지니어링에 관심이 있거나 데이터 아키텍트가 꿈인 분들이라면 꼭 소장하면서 두고두고 참고해야 할 책이라고 생각합니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."
#견고한데이터엔지니어링 #데이터엔지니어링 #데이터아키텍쳐 #데이터아키텍쳐전문가 #데이터아키텍처 준전문가 #DAP #DAsP #한빛미디어 #데이터수집 #빅데이터 #인공지능