















한빛미디어에서 제공받는 책으로 해당 리뷰를 작성하였습니다.

TL;DR
-
이 책은 ‘파이토치’를 기반으로 강화학습을 소개하는 교재이며, 교재에 소개한 이론은 수학과 파이썬 코드를 활용해서 설명하고 있다.
-
실습 환경을 구성할 때 약간의 에러가 발생할 수 있는데, 윈도우 사용자의 경우 SWIG을 먼저 설치해서 진행하면 좋다.
- Gym이 업데이트 되면서 약간의 오류가 발생할 수 있는데, 그러한 문제는 발생한 에러를 확인하면 쉽게 수정할 수 있다. 예를 들어, 2장 “강화학습의 수학적 기초”를 실습할 때 발생한 오류를 수정한 예제에서 확인할 수 있듯이 큰 문제가 아니니 오류를 자세히 확인해보자.
- 머신러닝/강화학습 연구자들에겐 ‘초급’ 수준의 기초 교재라 할 수 있으며, 강화학습을 처음 접하는 분들에겐 ‘중급’ 수준의 교재라 할 수 이다. 만약 강화학습을 처음 시작하는 분들이라면 개론적인 교재를 함께 읽어보길 권한다.
1
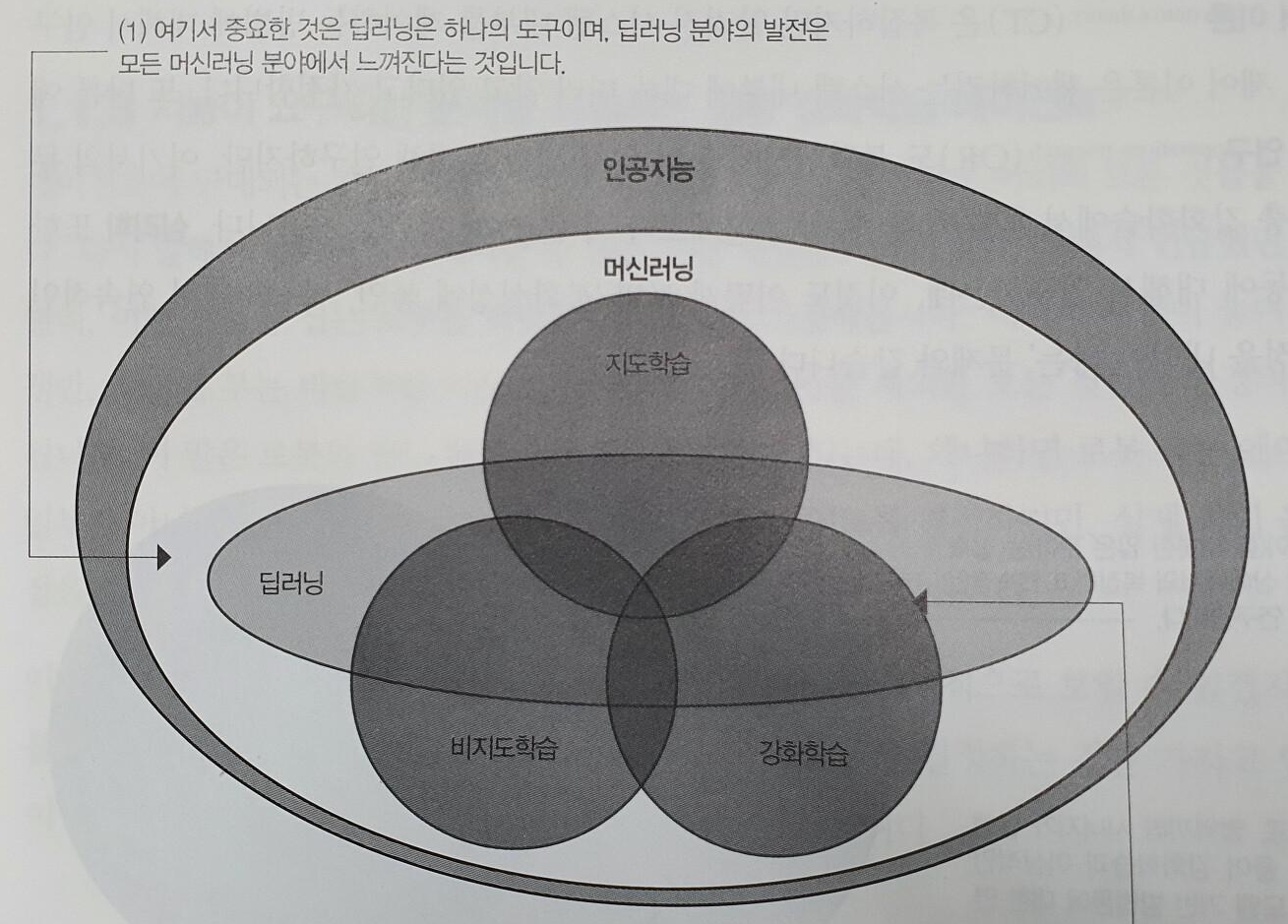
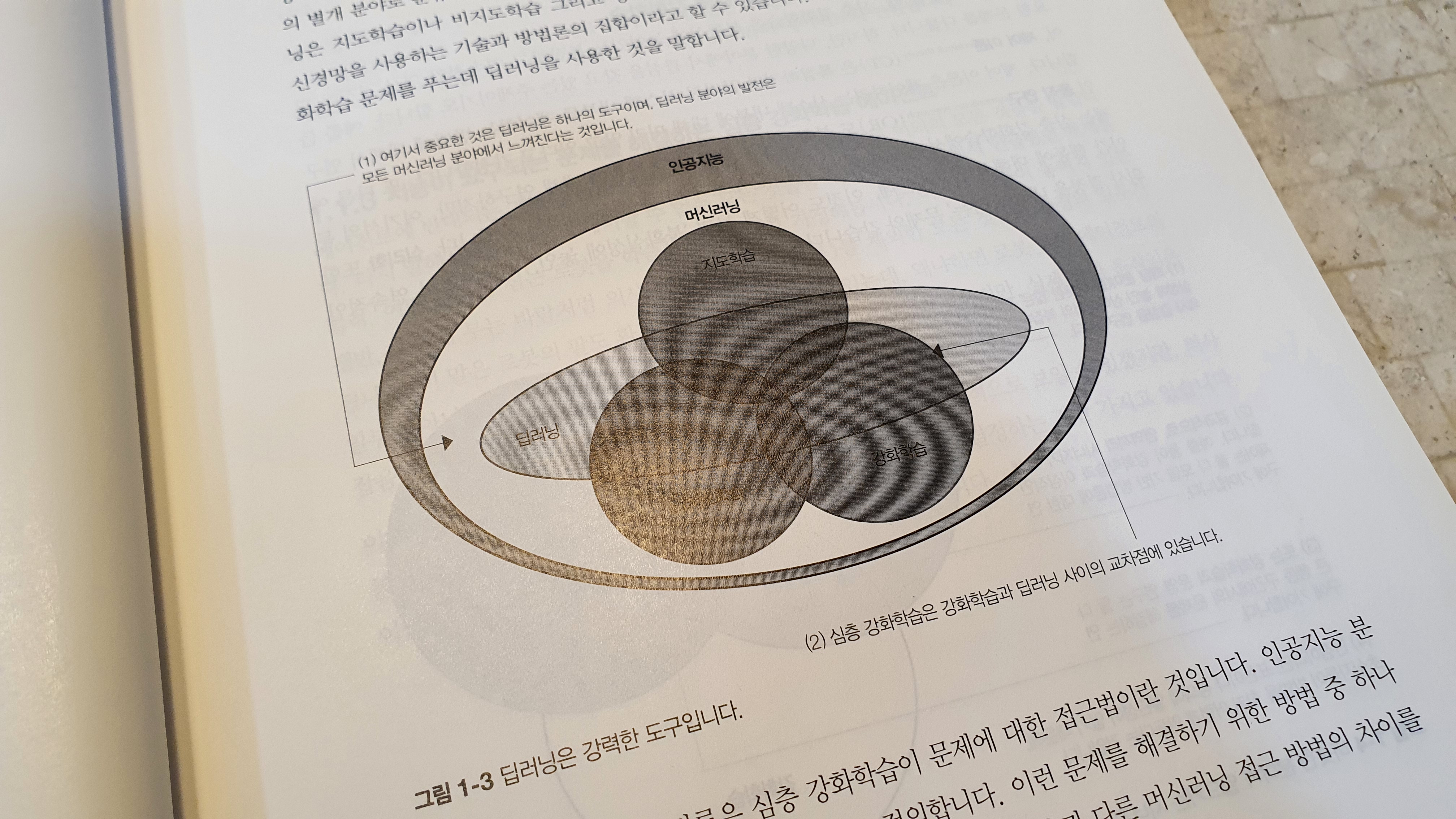
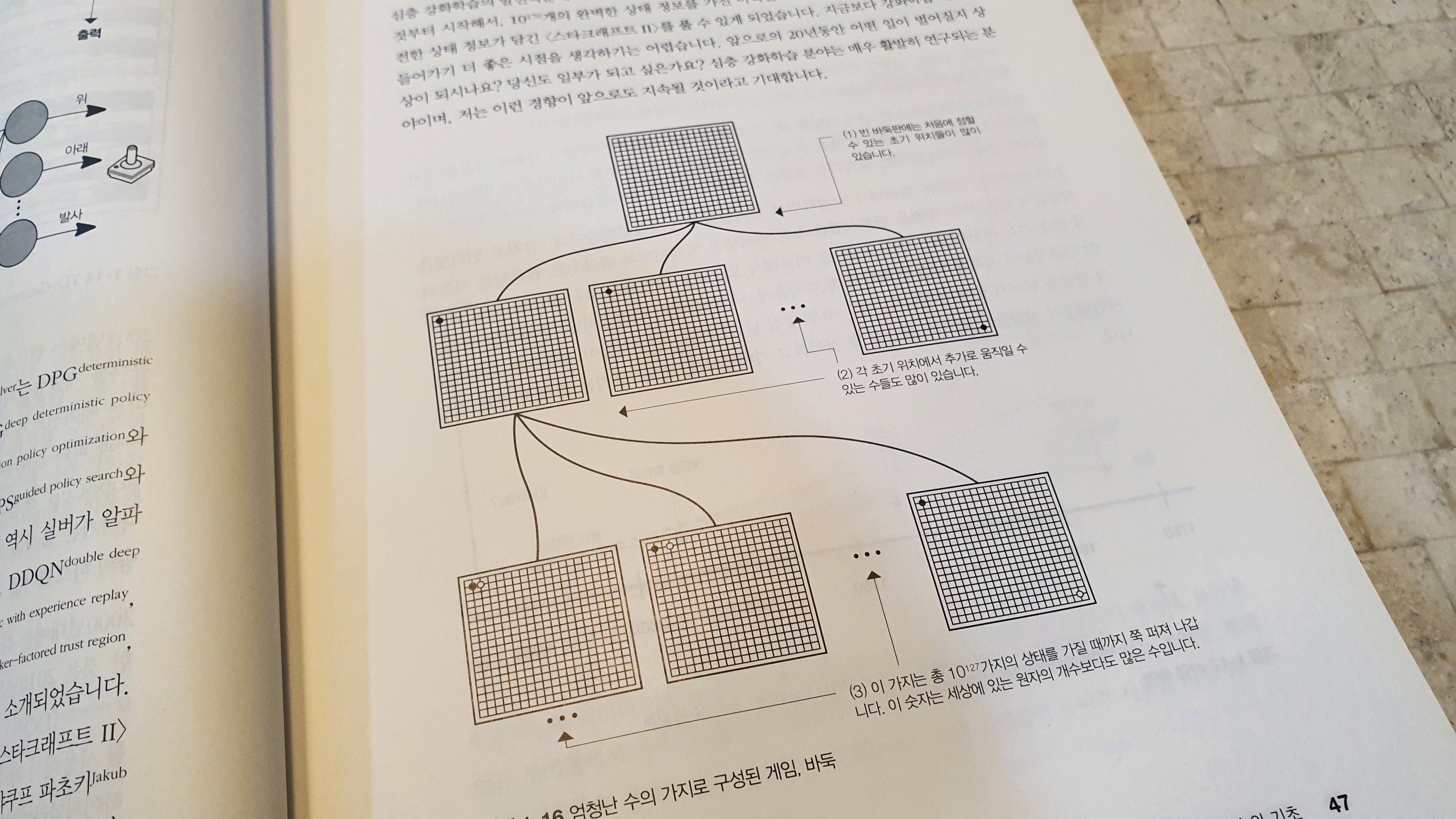
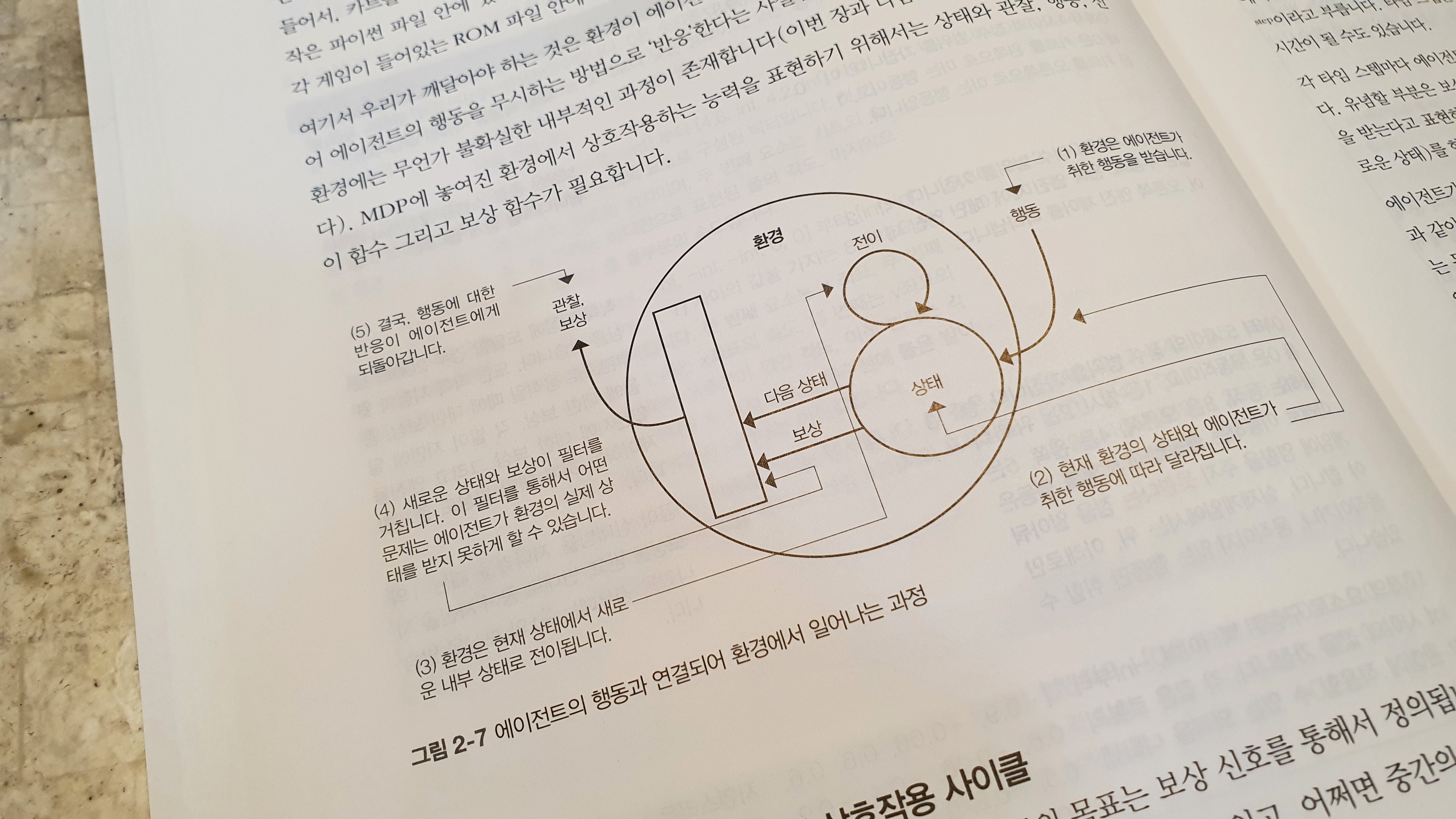
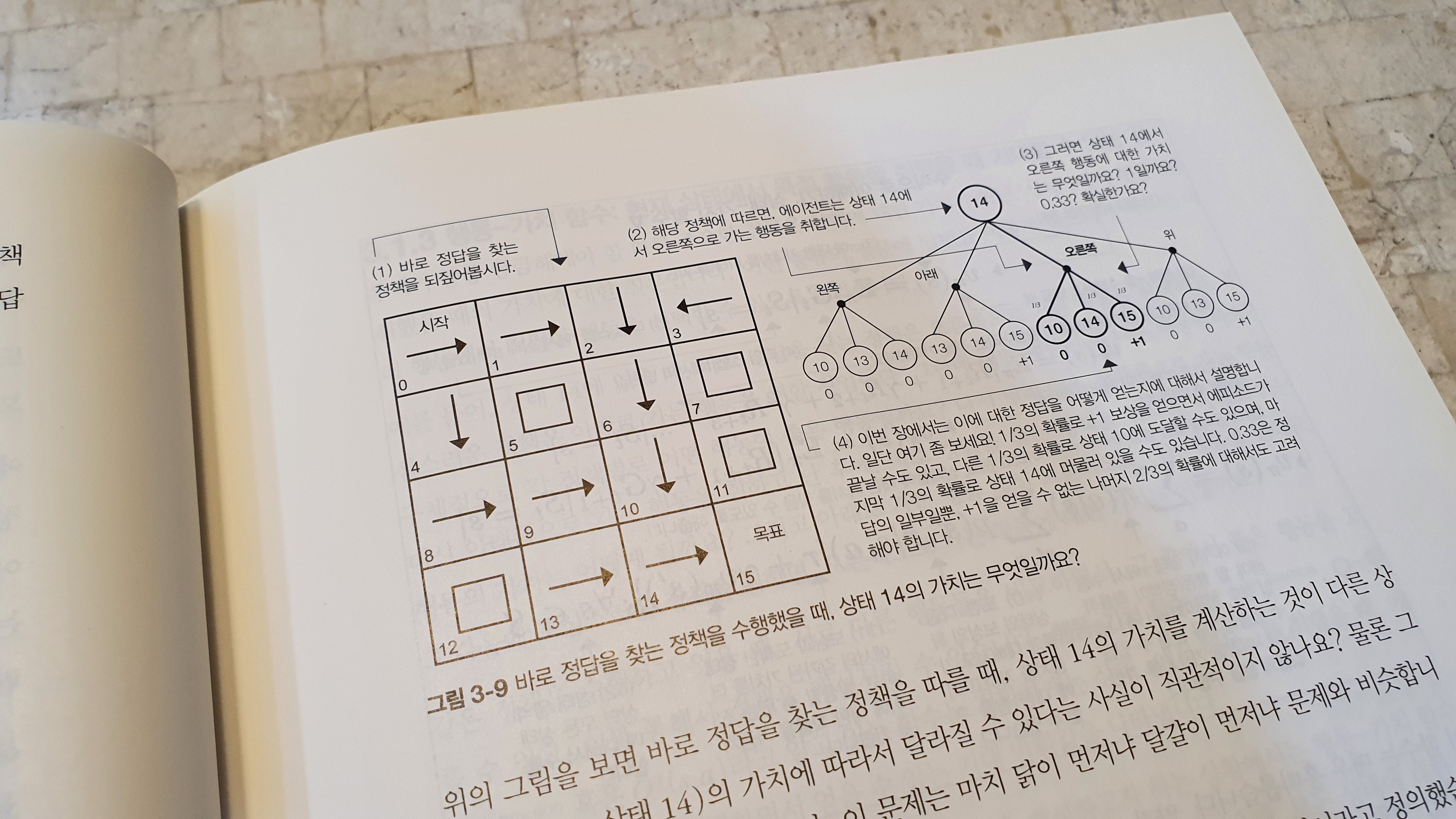
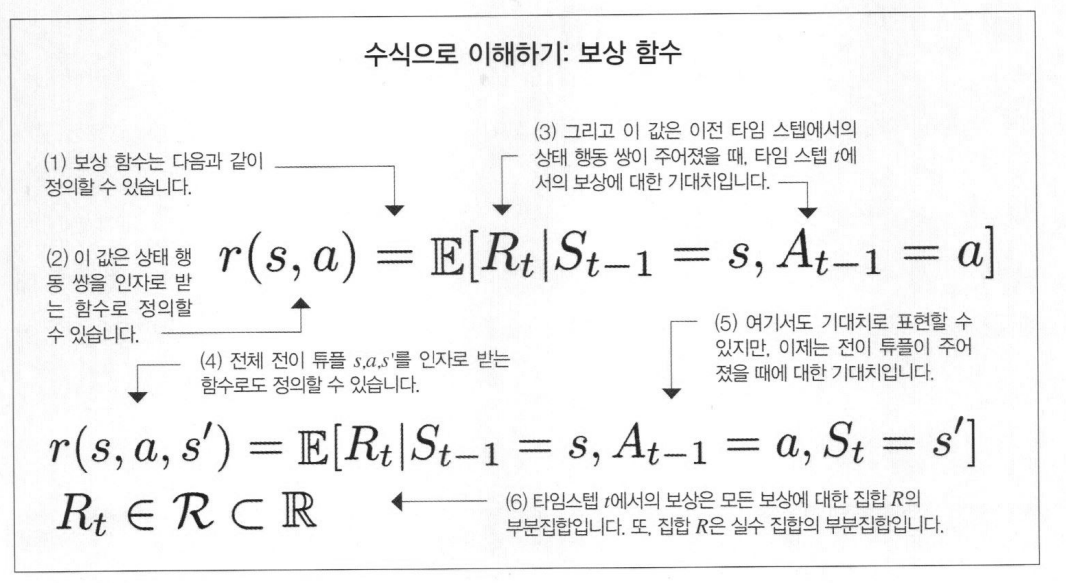
이 책은 강화학습 중 ‘가치 기반’과 ‘정책 기반’을 ‘파이토치’를 활용해서 차근차근 설명하는 교재다. 이 교재는 여타 교재에 비해서 수학 표기법 및 수학 이론에 대한 지식을 자세히 소개하고 있으며, 이러한 수학적 지식의 공허함을 파이썬 코드를 활용해서 차근차근 ‘메워주고’있다.
강화학습을 다루는 대부분의 교재가 가지는 큰 딜레마 중 하나는 ‘수학’과 ‘프레임워크’라 생각한다. ‘수학’의 경우 머신러닝이나 딥러닝에 비해서 표기법이 복잡하기 때문에 많은 교재들이 수학 표기법 및 수학적 지식을 전달하기 위해서 많은 노력을 하지만 수학은 언제나 어렵다. 그리고 수학이라는 작은 동산을 넘어가기 시작하면, OpenAI의 Gym과 같은 프레임워크 설치 및 활용법이라 할 수 있다. 특히, Gym과 같은 프레임워크에 대한 소개 및 적절한 가이드를 쉽게 찾을 수 없다는 점이 강화학습을 학습할 때 겪게되는 일상이다.
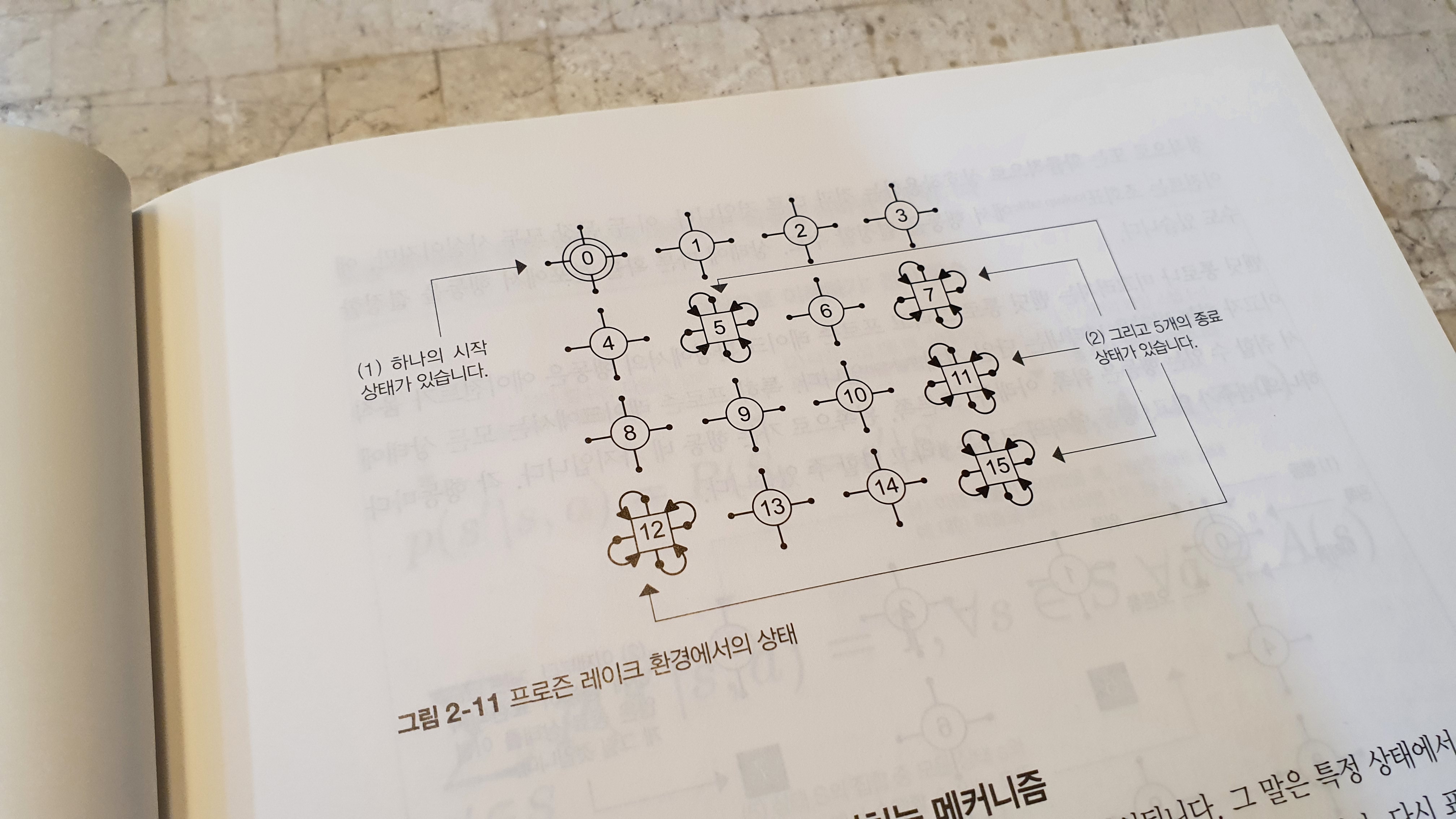
2
강화학습 자체가 가지는 난이도도 있지만, 실습이 쉽지 않다는 점도 한 몫 한다. 만약 자신이 ‘우분투’와 같은 리눅스 배포판을 주력으로 사용하고 있다면 2장의 예제를 손쉽게 실행할 수 있다. 필자도 연구에 사용하는 우분투 서버에선 무리 없이 진행할 수 있었지만, 현재 집에서 가끔 사용하는 윈도우 PC의 경우 SWIG 패키지가 설치되지 않아서 Box2D 설치시 오류가 발생했다. 이러한 오류의 경우 파이썬을 잘 활용하시는 분들은 손쉽게 처리할 수 있지만, 강화학습을 처음 접하거나 해당 패키지 사용법을 처음 접하는 분들에게 조금 어려울 수 있다.
그리고 필자와 같이 연구를 중심으로 머신러닝을 접하는 분들에게 파이토치(PyTorch)는 매우 반갑고 즐거운 일이지만, 텐서플로 사용자의 경우 새로운 형태의 프레임워크를 배워야 한다는 부담감이 있다는 점에서 교재를 선택할 때 주의를 요한다.
3
이 교재를 공부하면서 느꼈던 점은 ‘실습환경’을 잘 갖춘다면 강화학습을 학습하시는 분들에게 굉장히 좋은 교재라는 점이다. 이 책은 크게 2부분으로 나눌 수 있다(1장과 13장을 제외). 강화학습을 시작하는 분들에게 좋은 참고가 될 1부(2장~7장)와 딥러닝 프레임워크인 파이토치를 사용해서 기초적인 내용을 연습하는 2부(8장~12장)로 나눌 수 있다.
1부의 경우 OpenAI의 Gym을 사용해서 실습을 진행하고 있고, 교재에서 소개하는 모든 이론에 대한 수학적인 부분은 코드를 활용해서 직접확인 할 수 있다. 만약 1부(2장~7장)에서 소개하는 내용이 쉽게 이해되지 않는다면 강화학습 첫걸음(아서 줄리아니), 알파고를 분석하며 배우는 인공지능(오츠키 토모시)를 참고하면 좋을 듯 하다. 2부의 경우 머신러닝 연구자의 대부분이 파이토치를 활용할 수 있을 것으로 예상되지만, 파이토치가 어색하다면 파이토치 관련 교재를 함께 진행하길 권한다.
강화학습을 주제로 나온 교재 중에서 핵심적인 이론적을 체계적으로 소개한다는 점에서 추천하며, 처음 접하는 분들의 경우 강화학습의 개론서를 참고하면서 진행하면 더 좋을 듯 싶다. 무엇보다 강화학습을 필요로 하는 연구자라면 한번 꼭 읽어보길 강권한다.