[도서 소개]
효율의 끝판왕, 머신러닝 파이프라인으로 가장 손쉽게 자동화를 구축하는 방법!
많은 기업이 머신러닝 프로젝트에 수백억씩 투자한다. 안타깝지만 모델을 효과적으로 배포하지 못하면 엄청난 투자가 성과로 이어지기 어렵다. 이 책은 텐서플로 생태계를 사용하여 머신러닝 파이프라인으로 자동화하는 실용적인 방법을 단계별로 안내한다. 배포 시간을 며칠에서 몇 분으로 단축하여 레거시 시스템을 유지하고 관리하는 대신 새로운 모델 개발에 집중할 수 있도록 돕는 기술과 도구를 소개한다.
데이터 과학자, 머신러닝 엔지니어 및 데브옵스 엔지니어는 모델 개발을 넘어 데이터 과학 프로젝트를 성공적으로 제품화하는 방법을 배울 수 있으며, 관리자는 팀을 지원하는 데 필요한 역할과 업무를 더 잘 이해할 수 있을 것이다.
[목차]
CHAPTER 1 머신러닝 파이프라인
CHAPTER 2 TFX - 텐서플로 익스텐디드
CHAPTER 3 데이터 수집
CHAPTER 4 데이터 검증
CHAPTER 5 데이터 전처리
CHAPTER 6 모델 학습
CHAPTER 7 모델 분석 및 검증
CHAPTER 8 텐서플로 서빙을 사용한 모델 배포
CHAPTER 9 텐서플로 서비스를 사용한 고급 모델 배포
CHAPTER 10 고급 TFX
CHAPTER 11 파이프라인 1부: 아파치 빔 및 아파치 에어플로
CHAPTER 12 파이프라인 2부: 쿠베플로 파이프라인
CHAPTER 13 피드백 루프
CHAPTER 14 머신러닝을 위한 데이터 개인정보 보호
CHAPTER 15 파이프라인의 미래와 다음 단계
[대상 독자]
- 일회성 머신러닝 모델 학습을 넘어 데이터 과학 프로젝트를 성공적으로 출시하고자 하는 데이터 과학자와 머신러닝 엔지니어
- 프로젝트 관리자, 소프트웨어 개발자, 데브옵스 엔지니어
[주요 내용]
- 머신러닝 파이프라인 구축 단계 이해
- 텐서플로 익스텐디드(TFX)를 사용한 파이프라인 구축
- 아파치 빔, 아파치 에어플로, 쿠베플로 파이프라인을 사용한 머신러닝 파이프라인 조정
- 텐서플로 데이터 검증 및 변환을 사용한 데이터 작업
- 텐서플로 모델 분석을 사용하여 모델 세부 분석
- 모델 성능의 공정성과 편향성 조사
- 모바일 장치용 텐서플로 서빙 또는 텐서플로 라이트(TFLite)로 모델 배포
- 개인 정보를 보호하는 머신러닝 기술
[서평]
지난 몇 년동안 머신러닝 분야는 엄청나게 발전 했습니다. GPU의 광범위한 가용성과 BERT와 같은 트랜스포터나 DCGAN과 같은 DANs등 새로운 딥러닝 개념의 등장으로 AI프로젝트의 수가 급증 했습니다. AI 스타트업의 수는 어마하게 생겨 났습니다. 최신 머신러닝 개념을 조직의 모든 종류의 비즈니스 문제에 더 많이 적용하고 있습니다.
아마 앞으로는 대부분의 비즈니스에 AI가 적용될것이라 생각해봅니다. 데이터 과학자와 머신러닝 엔지니어가 개발 속도를 높이고, 재사용하고, 관리 및 배포하는데 활용할 개념과 도구에 관한 좋은 자료가 부족합니다. 가장 필요 한 것은 바로 머신러닝 파이프라인의 표준화 압니다. 머신러닝 파이프라인은 머신러닝 모델을 가속, 재사용, 관리 및 배포하는 프로세스를 구현하고 표준화 합니다. 10여년 전 지속적인 통합과 지속적인 배포를 도입하면서 많은 변화가 있었습니다. 이런 CI/CD 프로세스는 몇개의 도구와 개념 덕분에 크게 간소화 되었습니다.
데이터 과학자와 머신러닝 엔지니어는 소프트웨어 엔지니어링에서 워크플로에 대해 많이 배울수 있습니다.
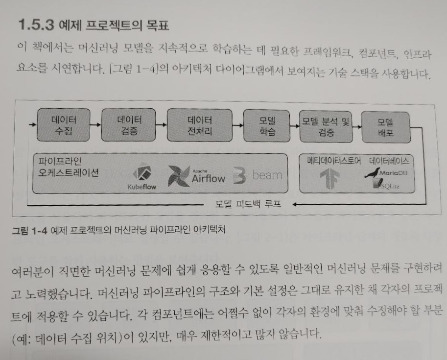
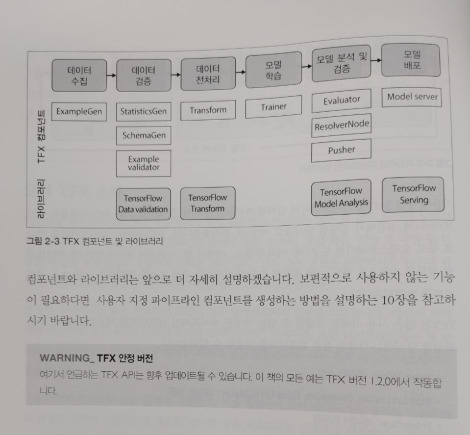
모델을 프로덕션에 배포하는 것을 목표로 하는 대부분의 데이터 과학 프로젝트는 대규모 팀을 갖추지 못합니다. 따라서 처음부터 전체 파이프라인을 구축하기가 어렵습니다. 머신러닝 프로젝트가 시간이 지나면서 성능이 저하되거나, 데이터 과학자가 기본 데이터가 변경되었을 때 오류를 수정하는데 많은 시간을 할애하거나, 모델이 널리 사용되지 않는 일회성 작업으로 변한다는 뜻입니다. 자동화되고 재현가능한 파이프라인은 모델 배포를 도와 줍니다. 파이프라인에는 다음 단계가 있어야 합니다.
-
데이터를 효율적으로 버전화하고 새로운 모델 학습 실행을 시작
-
새로운 데이터의 유효성을 확인하고 데이터 드리프트를 확인
-
모델 학습 및 검증을 위해 데이터를 효율적으로 전처리
-
머신러닝 모델을 효과적으로 학습
-
모델 학습을 추적
-
학습시키고 튜닝된 모델을 분석하고 검증
-
검증된 모델을 배포
-
배포된 모델을 스케일링
-
피드백 루프를 사용해 새로운 학습 데이터를 수집하고 성과 지표를 모델링
이책에서는 머신러닝 파이프라인 전체를 처음부터 끝까지 따라 하다보면 머신러닝 프로젝트에서 파이프라인을 구축 할수 있는 역량을 배울수 있을거라 생각합니다.
"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."